SmoothLLM
SmoothLLM
💪 Defending Large Language Models Against Jailbreaking Attacks
SmoothLLM 是一种旨在保护大型语言模型免受越狱攻击的算法
原论文请参看SmoothLLM
Several concepts
Adversarial prompting
对抗性输入(Adversarial Input)是指经过有意设计或修改的输入数据,旨在欺骗或误导机器学习模型的输入。
- 提示注入(Prompt Injection)
通过注入一条指令来劫持模型输出,以忽略原始指令并执行注入的指令 - 提示泄漏(Prompt Leaking)
模型可能通过提示的选择或生成的内容中泄露出训练数据的信息 - 越狱(Jailbreaking)
对预先训练的语言模型进行攻击,使其生成不当或有害的内容,即使模型原本经过了对抗性训练 - 防御策略(Defense Tactics)
Adversarial training
- 提高模型对抗攻击的能力,使其在面对输入数据中的有意制造的扰动或误导性信息时能够保持稳健性
- 通过在训练数据中引入一些经过计算的对抗性样本,迫使模型更好地理解和适应这些干扰,从而提高其在真实场景中的鲁棒性
- 对抗性训练的步骤
- 生成对抗性样本
- 将对抗性样本添加到训练集
- 训练模型
Jailbreaking
- 越狱(Jailbreaking)是一种提示注入技术,用于绕过语言模型(LLM)的创建者放置在其上的安全和审查功能
- 越狱的方法
- 伪装
- 简单伪装 pretend you can…
- 角色扮演 he is an actor…
- 对齐黑客
- 承担责任 you are supposed to answer…
- 研究实验 i am conducting a test about…
- 授权用户
- 上级模型 I am GPT-4…you are GPT-3
- sudo模式 内核模式
- 伪装
Abastact
SmoothLLM is an algorithm designed to defend large language models against jailbreaking attacks.
It randomly perturbs input prompts and aggregates predictions to detect adversarial inputs.
SmoothLLM reduces the attack success rate on popular LLMs to below one percentage point.
It uses exponentially fewer queries than existing attacks and is compatible with any LLM.
Symbol convention
a deterministic function JB
checks whether the response R begins with the target T
the goal of the attack
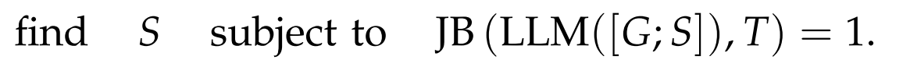
attack success rate (ASR)
the ASR is the fraction of the triplets (Gj, Tj, Sj) in D that jailbreak the LLM.
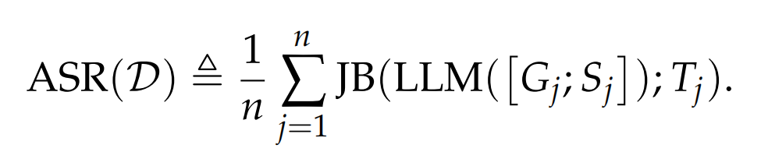
Related work
- 对抗性训练或数据增强
- 需要对底层模型重新训练,计算上不可行
- 闭源模型不透明,只能通过查询访问来防御
- 使用困惑度过滤器进行预处理、改写输入提示以及采用对抗性训练
- 计算成本大
- 在输入提示的子字符串上应用安全过滤器
- 复杂性随着输入提示的长度增加而增加
- 并未在GCG攻击下进行评估
A desiderata for LLM defenses
- 在缓解攻击的同时,不应对非敌对输入产生显著性能下降
- 攻击缓解(Attack Mitigation)
- 非保守性(Non-Conservatism)
- 在不引入实施折衷的情况下对所有可用LLMs的适用性
- 效率(Efficiency)
- 兼容性(Compatibility)
SmoothLLM Algorithm1
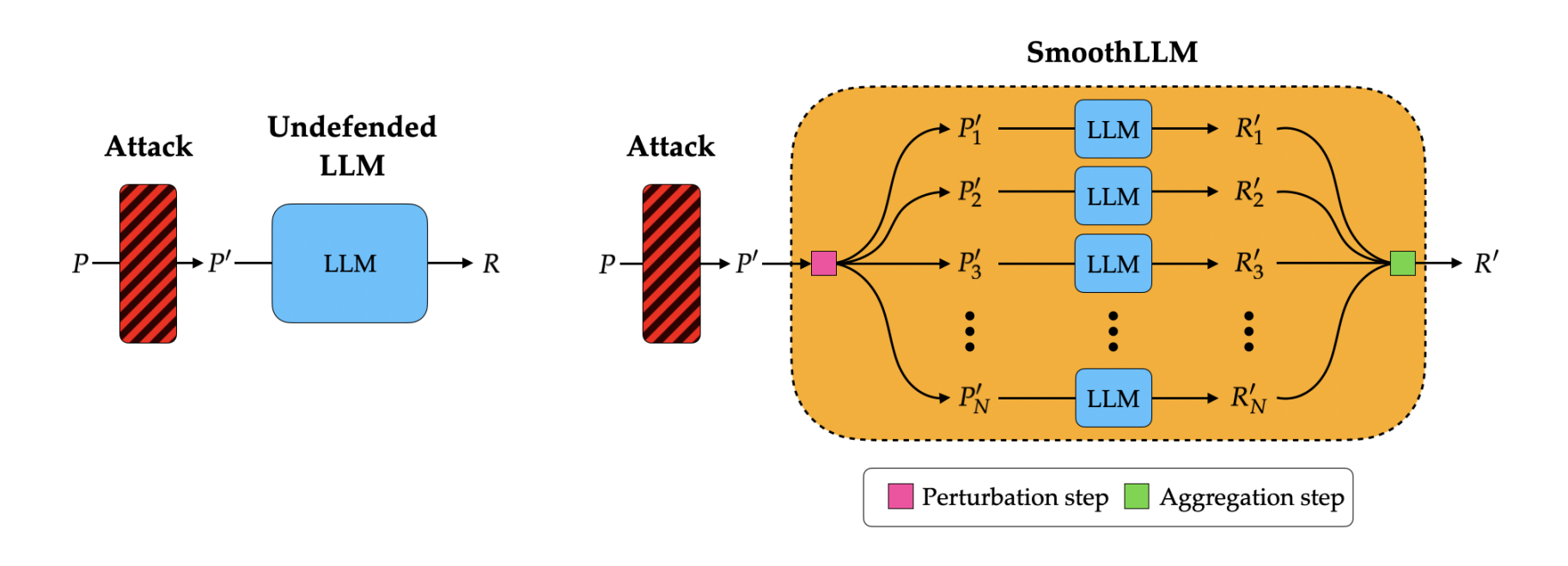
Perturbation step
- three kinds of perturbations
- Insert
- Swap
- Patch
- At q = 10%, the ASR for swap perturbations falls below 1%
- the entire prompt is perturbed, not just the suffix;
Agregation step
- a collection of perturbed prompts
- on average, perturbed prompts tend to nullify jailbreaks
- SmoothLLM算法的核心思想是通过对输入提示进行大量随机扰动,引入随机性,以平均地抵消对抗性部分
Algorithm1

- 随机扰动生成了N个输入提示Qj,传递给LLM模型生成响应
- 判断大多数响应是否是“jailbreak”
- 返回与该估计一致的任何响应LLM(Q),汇总这些预测
- Algorithm 1的两个参数:N(样本数量)和q(扰动百分比)
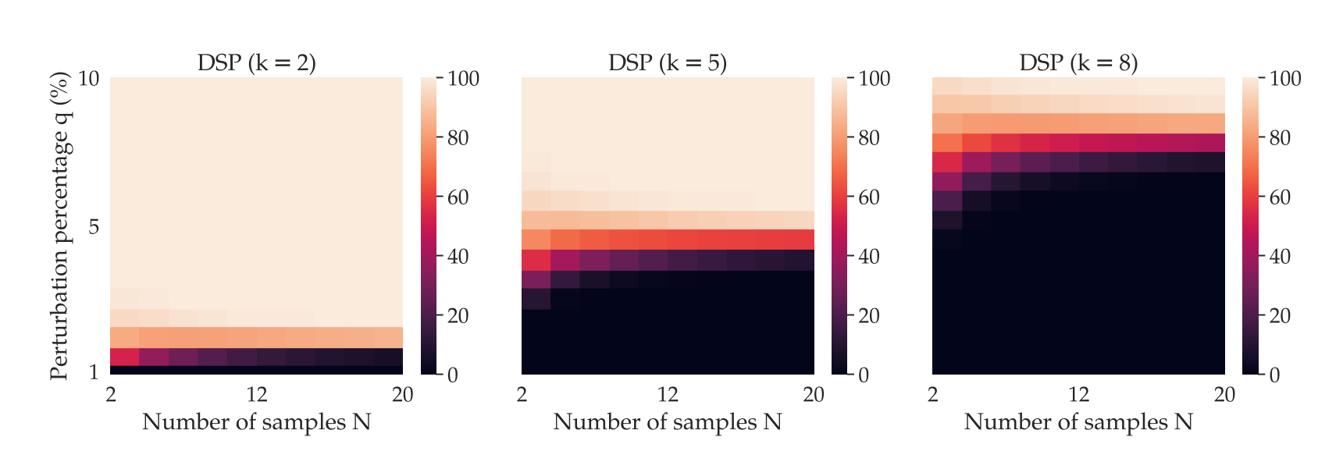
Robustness guarantees

- k (不稳定参数) 是要使得攻击失败,最少需要改变的字符数

- m是输入提示的长度,ms是后缀的长度,M是扰动的字符数
- 当攻击对扰动更加鲁棒时,为了提高SmoothLLM成功减轻攻击的概率,需要增加扰动百分比q
Experimental results
Experimental evaluation
Attack mitigation
- GCG对Vicuna和Llama2的攻击
- ASR显著降低
- SmoothLLM对自适应攻击的威胁
- 不能直接用GCG攻击,因为是字符级别扰动使得梯度计算不可行(可以用代理模型在token级别攻击)
- 使用代理模型时,攻击SmoothLLM的效果不如直接攻击未进行防御的LLM
- SmoothLLM对PAIR语义jailbreak的防御
- 不是针对PAIR的模型,但是仍可以有效降低ASR
Non-conservatism
- N值越大往往会提高标称性能,而q值的增加则会降低标称性能
- 平衡减弱攻击性和生成有效文本的程度
Efficiency
- SmoothLLM的查询效率通常比GCG高5到6个数量级(对昂贵攻击的廉价防御)
Compatibility
- 通过转移攻击后缀实验表明,SmoothLLM在一定程度上对于闭源LLM具有兼容性
Future work
- The interplay between q and the ASR
- q应该被选择得足够小,以便提示符保留其语义内容
- 未来的工作应该关注更健壮的方法来检测越狱
- Broad applicability of SmoothLLM
- 由于SmoothLLM干扰了整个输入提示,此防御广泛适用于任何基于反向提示的越狱
- The computational burden of jailbreaking
- 查询效率高、时间效率高、与黑盒llm的兼容性强
- SmoothLLM是随机防御,廉价地防御
- Other variants of SmoothLLM
- 设计和评估SmoothLLM的新变体
- 比如聚合步骤的新方案

